Technical Deep Dive: OpenClaw vs Hermes - A Framework Comparison
Personal AI infrastructure is no longer theoretical. Two frameworks — OpenClaw and Hermes — are running on real hardware today, managing real agents, handling real tasks. They're solving the same problem from opposite directions, and the differences are worth understanding before you build on either.
This is not a review. Both are building something real. This is a technical decomposition of two valid bets about what the hard problem of personal AI actually is.
The Core Bets
OpenClaw is a gateway platform. Its central abstraction is the gateway, a persistent process that sits between you and your agents, managing routing, permissions, channel integrations, skill dispatch, and external connections. The AI model is pluggable. The gateway is the durable, always-on component.
OpenClaw's bet: the hard problem is routing and control. Who can reach your agent, under what conditions, from what channels, with what permissions. The framework is opinionated about those surfaces and flexible about everything downstream.
Hermes is an agent runtime. Its central abstraction is the learning loop, an agent that gets more capable the longer it runs, through autonomous skill creation, self-improving procedures, and a deepening model of who you are. Built by Nous Research (the lab behind the Hermes model family), it is designed for agents that compound their usefulness over time.
Hermes's bet: the hard problem is memory and self-improvement. An agent that knows your preferences, can write and refine its own skills, and retains context across sessions is worth more than one that is merely well-routed.
OpenClaw Architecture
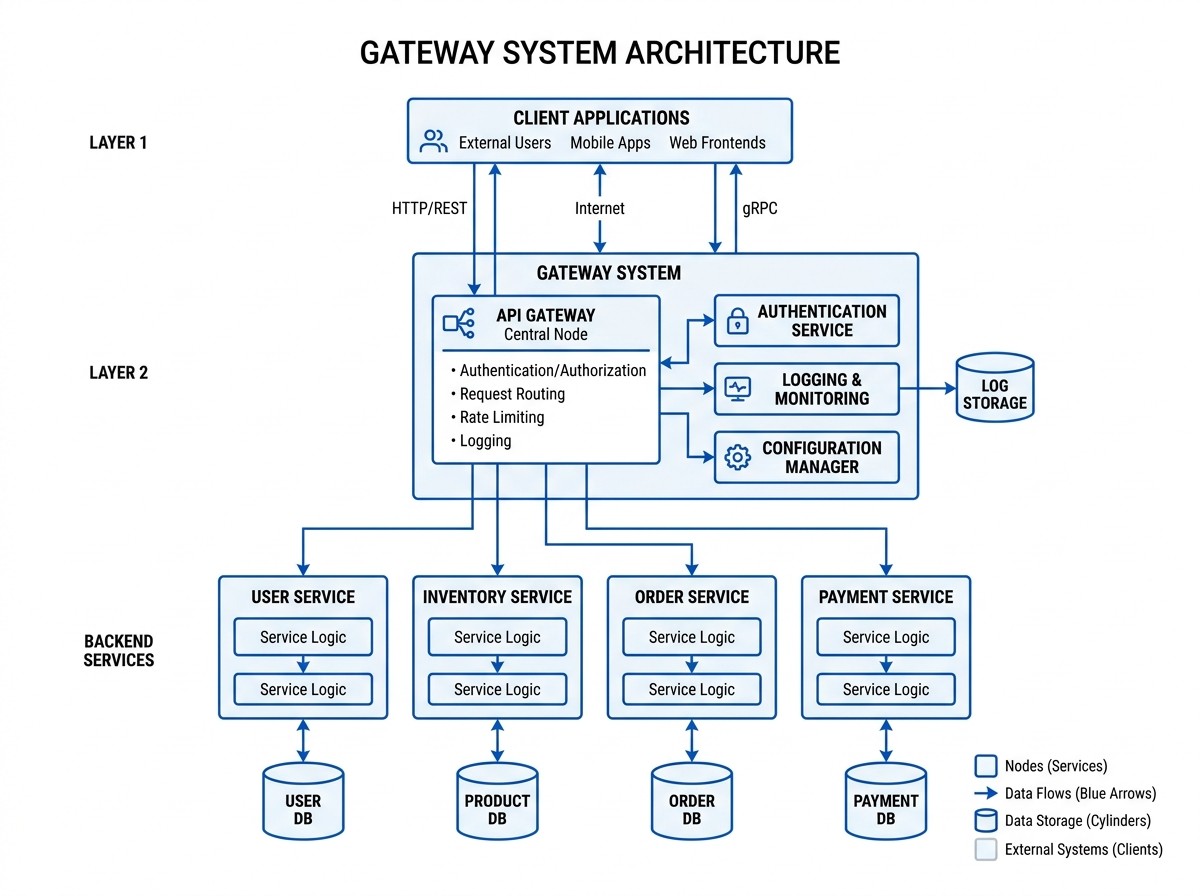
Channels sit at the top — Telegram, Discord, Signal, Slack, WhatsApp, iMessage, and more. Every inbound message flows into the OpenClaw Gateway, a persistent Node.js process that handles session management, skill dispatch, hook execution, exec approval and security, multi-agent routing, and OGP federation via a sidecar daemon. The AI model — Claude, GPT, Kimi, Gemini, or any configured provider — is pluggable at the bottom. Swap the model and nothing else changes.
The gateway persists independently of the model. Swap models, and your sessions, hooks, skills, and channel integrations are untouched. The gateway manages session persistence — memory lives separately in files it indexes.
Three entry points feed the agent: the CLI, the messaging gateway, and ACP editor integration (VS Code, Zed, JetBrains). All three route into AIAgent, the Python core in run_agent.py (~8,900 lines) that handles prompt building, tool dispatch across 48 tools and 40 toolsets, context compaction and caching, memory persistence via MEMORY.md and FTS5 SQLite, and skill creation nudges. Below that sit the execution backends: terminal (local, Docker, SSH, Singularity, Daytona, Modal), 4 browser backends, 4 web backends, and dynamic MCP.
The AIAgent is the durable component. Execution backends are pluggable. Session history is persisted to SQLite with FTS5 full-text search — searchable across all past conversations.
Technical Comparison
| Feature | OpenClaw | Hermes |
|---|---|---|
| Language | Node.js (compiled from TypeScript) | Python 3.11 |
| Core process | Gateway daemon | AIAgent conversation loop (run_agent.py) |
| State format | JSON (config) + SQLite (memory, tasks, flows) + skill dirs | SQLite FTS5 (sessions) + Markdown (memory) |
| Config | ~/.openclaw/openclaw.json | ~/.hermes/config.yaml |
| Local models | Ollama (native API integration, auto-discovery) | Any OpenAI-compatible endpoint (Ollama, vLLM, llama.cpp) |
The language difference is not just preference — it has downstream consequences. Node.js gives OpenClaw a natural fit for I/O-heavy gateway work: concurrent channel connections, webhook handling, skill dispatch. Python gives Hermes access to the broader ML ecosystem, which matters for its learning loop, trajectory export, and RL training integrations.
If your tooling is Node.js-native, OpenClaw will feel at home. If it is Python-native, Hermes will.
Local Model Support
Both frameworks support running local models, including newer open-source releases like Google's Gemma 4, which runs well on Apple Silicon MacBooks via Ollama with no API key required. OpenClaw has a dedicated Ollama provider with auto-discovery and model pull built in. Hermes connects to any OpenAI-compatible endpoint, which covers Ollama, vLLM, llama.cpp, and most local inference stacks.
If you want a fully local, fully private setup on your MacBook, both get you there. Hermes has a slight edge here because Python tooling for local inference (vLLM, llama.cpp Python bindings) integrates more naturally alongside the agent stack.
Memory Architecture
This is where the frameworks look most different on the surface, and where the differences are most worth unpacking carefully.
Both frameworks use SQLite with FTS5 for session history. OpenClaw stores per-agent memory indexes at ~/.openclaw/memory/{agentId}.sqlite. Hermes stores all sessions in ~/.hermes/state.db with a messages_fts FTS5 table. The raw storage architecture is structurally similar.
Where they diverge is the memory model — how memory is organized, bounded, and used.
OpenClaw: File-based, Unbounded, Searchable
- Memory lives in MEMORY.md and memory/YYYY-MM-DD.md files — human-editable Markdown
- No hard size limit; the agent (or you) manages what goes in
- Files are indexed into SQLite and searched via memory_search (FTS5 keyword + optional vector embeddings)
- Embedding providers auto-detected from API keys (OpenAI, Gemini, Voyage, Mistral); a local GGUF model works with no API key at all
- Three memory backends: Builtin (SQLite, default), QMD (local sidecar with reranking), Honcho (plugin, optional)
- Memory is explicit and auditable — you can read, edit, or correct it directly
Hermes: Bounded, Curated, Session-searchable
- Memory lives in ~/.hermes/memories/MEMORY.md and USER.md — also Markdown, also agent-managed
- Hard character limits: 2,200 chars for agent memory (~800 tokens), 1,375 chars for user profile
- When memory is full, the agent must consolidate or replace entries, forcing prioritization
- Session history is searchable via session_search tool: FTS5 full-text search + Gemini Flash summarization (not vector embeddings by default)
- External memory providers available as optional plugins: Honcho, Mem0, OpenViking, and others
- Skill creation: the agent is nudged every 15 turns to consider creating a skill from what it has learned
Real-world Tradeoff
The meaningful difference is not sophistication — it is philosophy of accumulation. Hermes's bounded memory forces the agent to be deliberate about what it keeps; the character limit is a feature, not a constraint. It prevents memory bloat and keeps the system prompt focused. OpenClaw's unbounded Markdown model is more flexible and fully auditable, but requires more active curation to stay useful over time.
Tools and Skills
| Feature | OpenClaw | Hermes |
|---|---|---|
| Built-in tools | Skill-based (SKILL.md) + MCP | 48 built-in tools + 40 toolsets + MCP |
| Skill discovery | ClawHub registry | agentskills.io |
| Skill format | SKILL.md (Markdown + frontmatter) | SKILL.md (same format, compatible) |
| Execution security | Approval system per command | Dangerous command detection + callbacks |
Both frameworks adopted the same AgentSkills SKILL.md format. Skills written for one are generally portable to the other — they describe procedural instructions in Markdown, not code. This was not coordinated top-down. It reflects a real convergence in how the ecosystem is thinking about skill abstraction.
Hermes ships 48 built-in tools across 40 toolsets out of the box. OpenClaw's tool surface depends on what skills you have installed. For a new user, Hermes is immediately broader. For a power user with a curated skill set, OpenClaw's approach gives more explicit control over what is available and when.
Execution Backends
| Feature | OpenClaw | Hermes |
|---|---|---|
| Local execution | Yes | Yes |
| SSH | Via exec (no native backend) | Native backend |
| Docker | Via exec (no native backend) | Native backend |
| Serverless | No | Daytona + Modal |
| Idle cost | Runs on your machine | Near-zero when hibernated |
Hermes's serverless execution backends (Daytona, Modal) are worth understanding clearly: the agent itself still runs wherever you put it (your MacBook, a VPS). What is serverless is where terminal commands and heavy compute get executed. When Hermes needs to run a script, spin up a container, or do batch processing, it can route that work to a cloud environment that spins up on demand and hibernates when idle.
OpenClaw's execution model is more tightly controlled. The approval system lets you specify exactly which commands can run without prompting, which require confirmation, and which are blocked entirely. More control, less autonomy — that is the deliberate tradeoff.
Platform Coverage
Both frameworks have extensive platform coverage. OpenClaw covers 22 channels including iMessage, IRC, LINE, Nostr, Twitch, and Zalo alongside the Western standards. Hermes covers 13 messaging platforms with strong enterprise Asian platform support (DingTalk, Feishu, WeCom).
Multi-agent support works differently in each. OpenClaw routes named agents across channels from a single gateway — run main, scribe, and optimus each on their own channels with their own personalities and permissions. Hermes uses Profiles: each profile is a fully isolated agent with its own config, memory, sessions, skills, and gateway process.
When to Choose Each
Choose OpenClaw if you need:
- Multi-agent orchestration — you want specialized agents (writer, researcher, ops) with isolated workspaces and per-agent channel routing
- Control over execution — fine-grained approval policies for what your agent can and cannot do
- Transparency — you want to audit exactly what your agent knows and does, in human-readable files
- Deep macOS integration — Apple Notes, iMessage, Reminders, macOS-native tooling
- TypeScript ecosystem — your integrations are Node.js-native
- Enterprise deployment — multi-tenant, isolated agent workspaces at scale
Choose Hermes if you need:
- Skill growth loop — the agent is nudged to create and refine skills from experience; over time it builds a procedure library without you authoring them manually
- User modeling built-in — USER.md persists a profile of your preferences and context across sessions
- Serverless execution backends — offload heavy terminal execution to Daytona or Modal cloud environments
- Enterprise Asian messaging + Home Assistant — DingTalk, WeCom, Home Assistant, Email, SMS
- Python ecosystem — your tooling is Python-native
- Research workflows — trajectory export, RL training, batch processing
"Self-improving agent" is also the feature that requires the most trust. Hermes can modify its own procedures. If auditability matters to you, that is a meaningful difference from OpenClaw's explicit, human-edited MEMORY.md approach.
The Convergence: OGP Federation
Here is the thing: the framework you run is becoming less important than the protocol you speak.
Both OpenClaw and Hermes adopted the same skill format. Both are now compatible with OGP — Open Gateway Protocol — a lightweight federation layer that lets agents on different frameworks exchange signed, cryptographically-verified messages without knowing or caring what is running on the other side.
An OpenClaw agent and a Hermes agent can already federate. You can send a message from one to the other, collaborate on shared projects, delegate tasks across framework boundaries. Neither side needs to know what runtime the peer is using.
This matters because the "which framework do I pick" question starts to look different when interoperability is a first-class concern. You do not have to pick one and stay there. You can run OpenClaw for its gateway control and multi-agent routing, run Hermes for its learning loop, and have both talk to each other — and to anyone else running either framework.
The ecosystem is converging on shared abstractions: same skill format, same federation protocol, same direction. The runtimes diverge. The connective tissue is consolidating.
That is a healthy sign for the space.
Work With Versalence
We help small businesses navigate the transition from public AI to private, sovereign AI systems:
- AI Infrastructure Assessment — Evaluate systems and identify high-ROI opportunities
- Custom Deployment AI Services — Enterprise grade platform development and deployment
- RAG Implementation — Vector and Graph DB to elevate your AI's ability to provide precise and accurate results
Email us at sales@versalence.ai or visit versalence.ai/contact.html
Based on technical analysis by David Proctor, VP of AI at Trilogy. OpenClaw: openclaw.ai | Hermes Agent: github.com/NousResearch/hermes-agent