
Nvidia Licenses Groq LPU: Redefining AI Compute and GPU Strategy in 2026
In late December 2025, Nvidia confirmed a landmark non-exclusive technology licensing agreement with Groq, centered on Groq’s cutting-edge Language Processing Unit (LPU) architecture — a specialized chip optimized for AI inference. Alongside the license, Nvidia has welcomed key Groq executives, including founder and former CEO Jonathan Ross, to accelerate the integration of this technology into its broader ecosystem. Groq remains an independent entity, continuing to serve cloud customers and develop its platform — even as its core IP and talent feed into Nvidia’s roadmap.
This move, reported with a notional valuation near $20 billion, represents one of Nvidia’s most significant strategic shifts to date and signals broader changes in how AI workloads will be processed and what hardware infrastructure AI developers and enterprises will require by 2026 and beyond.
Why the Groq LPU Matters
To understand the impact, it’s necessary to differentiate compute roles in AI systems:
-
Training: Building AI models from datasets — historically dominated by GPUs due to their massive parallelism.
-
Inference: Running trained models to generate outputs — where latency, power efficiency, and throughput per cost become the defining metrics.
Groq’s LPU architecture is fundamentally designed for low-latency, high-throughput inference. Unlike GPUs that rely on external high-bandwidth memory and general-purpose parallel engines, LPUs use large on-chip SRAM and a deterministic compute model to minimize idle cycles and memory fetch waits. These design choices deliver substantially faster token generation with improved energy efficiency, traits critical for real-time, high-interactive AI applications.
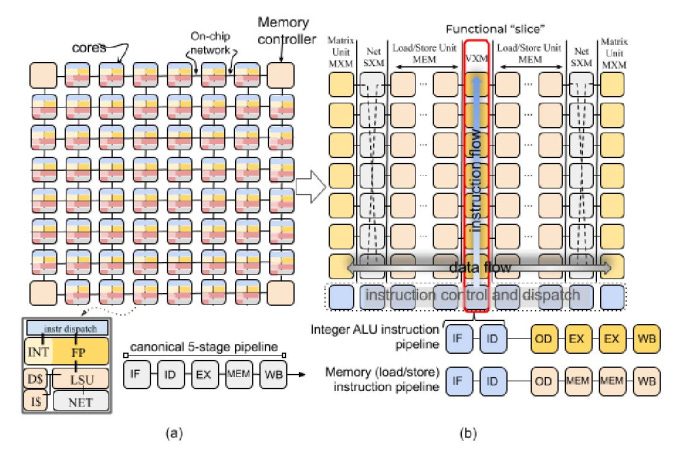
Strategic Rationale Behind Nvidia’s Licensing
This deal indicates a paradigm shift in Nvidia’s hardware strategy:
-
Inference as a First-Class Compute Tier: The industry has moved beyond a GPU-only view of AI. Real-time generative AI agents, conversational assistants, and other latency-sensitive applications demand hardware that can serve responses faster — a niche LPUs are inherently suited for.
-
Complement, Don’t Replace GPUs: Nvidia’s GPUs continue to dominate training workloads. The LPU technology augments this by offering a complementary inference engine, suggesting future Nvidia systems may blend GPU and LPU resources for optimal performance across the AI stack.
-
Talent and Innovation Infusion: Bringing Groq’s architects — especially those with deep domain knowledge like Jonathan Ross — into Nvidia accelerates R&D on inference-optimized silicon and supporting compiler technologies.
-
Regulatory Navigation: Structuring this as a license-and-talent deal rather than an outright acquisition helps Nvidia navigate competition and antitrust scrutiny while harvesting strategic advantages.
Implications for AI Models in 2026
1. New Hardware Tiers for Deployment
By 2026, the AI compute landscape will likely crystallize into a multi-slice architecture:
-
GPU clusters for heavy model training and large-batch inference.
-
LPUs and similar ASICs for high-throughput, low-latency inference in production systems.
-
Hybrid accelerators that orchestrate workload distribution based on model size, query patterns, and cost/performance targets.
AI platforms and infrastructure vendors must prepare for multi-architecture support in orchestration layers like Kubernetes, resource schedulers, and AI runtimes.
2. Model Optimization for Inference Efficiency
Engineering focus will shift further toward:
-
Quantized models (e.g., 8-bit/4-bit precision) to maximize inference throughput on LPUs.
-
Compiler pipelines that automatically map large model graphs onto heterogeneous hardware.
-
Split execution strategies, where large layers run on GPUs while final layers or real-time requests hit LPUs.
Expect a growing ecosystem of compilers and model translation tools that target new hardware primitives beyond CUDA.
3. Reduced GPU-only Dominance for Inference Workloads
AI developers and enterprises that assumed inference would continue to rely solely on GPUs will need to adapt:
-
Smaller, efficient inference accelerators may drive down cost per request.
-
Cloud providers could offer differentiated SLAs based on mixed GPU/LPU backends.
-
GPU demand for inference might plateau, with growth shifting toward specialized inference silicon.
Continuing reliance on GPU suites such as Nvidia TensorRT will likely evolve to incorporate LPU-aware execution paths.
GPU Requirements and Market Impact by 2026
The Nvidia-Groq licensing deal is a harbinger of major industry shifts:
1. Rebalance of Compute Demand
While GPUs remain essential for training tomorrow’s complex models, inference compute demand will draw from diverse accelerators, pressuring GPUs to compete on cost-efficiency rather than raw throughput in production settings. This realignment will influence:
-
Procurement strategies for data centers.
-
Cloud pricing models linking workload type to hardware cost.
-
Strategic differentiation among hardware vendors.
2. Competitive Hardware Innovation
Expect competitors like AMD, Google (TPUs), and bespoke silicon vendors to accelerate inference strategies, catalyzing:
-
More diverse accelerator ecosystems.
-
Standardized APIs for multi-chip orchestration.
-
Hardware abstraction layers that insulate model developers from underlying complexity.
The hardware stack may resemble modern CPU/GPU hybrids in PCs — with distinct silicon for specific workloads.
|
Stakeholder / Aspect |
Impact |
Insight |
|---|---|---|
|
AI / LLM Developers |
High |
They stand to gain from blending GPU and LPU power through Nvidia's software setup, tailoring inference for top speed (low latency, high tokens/sec) across models and scenarios - something that's been a pain point. |
|
Nvidia |
High |
It solidifies their lead by folding in a top inference rival's IP and people, smartly guarding against niche hardware stealing the show in deployment. |
|
Groq (Company) |
Critical |
Licensing brings in serious cash, sure, but losing leaders hits hard on operations and direction - that non-exclusive bit? It's a double-edged sword, freedom with strings. |
|
GroqCloud Customers |
Medium |
Continuity's promised for now, but the road ahead ties into whatever shakes out between Groq and Nvidia, with its ex-leaders now on the other side. |
|
Regulators (FTC/EC) |
Significant |
A prime example of sneaky competition tweaks without the merger label, poking holes in old antitrust playbooks and forcing fresh looks. |
|
Rival Chipmakers |
High |
Nvidia's now tougher, having grabbed a standout architecture - the race for inference edge just got steeper for everyone else. |
Conclusion: A Platform Shift Toward Better Inference
The Nvidia licensing of Groq’s LPU technology signals a turning point in AI compute architecture: a departure from GPU-centric thinking toward heterogeneous hardware integration where inference-specialized chips play a central role. By 2026:
-
Inference workloads will increasingly run on purpose-built accelerators, lowering costs and improving responsiveness.
-
Model developers will optimize across diverse backends, balancing latency, throughput, and cost.
-
Organizations will require infrastructure that intelligently routes workloads between GPUs and inference engines like LPUs.
This deal fundamentally reshapes AI hardware expectations and investment strategies for the coming years, ushering in a more nuanced and performance-efficient era of AI deployment.