Building a Fully Private RAG Chatbot — No Cloud, No Data Leakage
In an era where AI assistants are everywhere, most rely on cloud-hosted Large Language Models (LLMs) like OpenAI or Anthropic. For many businesses, this is a non-issue. But for organisations with sensitive internal knowledge — whether due to IP concerns, compliance requirements, or security mandates — sending data to a public LLM is simply not an option.

Recently, Versalence AI delivered a fully private Retrieval-Augmented Generation (RAG) chatbot for a client with one clear mandate:
“Build an AI chatbot that can answer from our internal knowledge base — but without sending a single byte of data to any cloud-based LLM.”
The Challenge
The client’s environment was governed by strict data policies. Even anonymised or processed content was prohibited from leaving their infrastructure. This meant:
-
No OpenAI, Anthropic, or similar cloud APIs
-
No hybrid hosting where prompts are routed to the internet
-
No vector database hosted on third-party infrastructure
We needed to deliver enterprise-grade AI capability while keeping 100% of the data processing local.
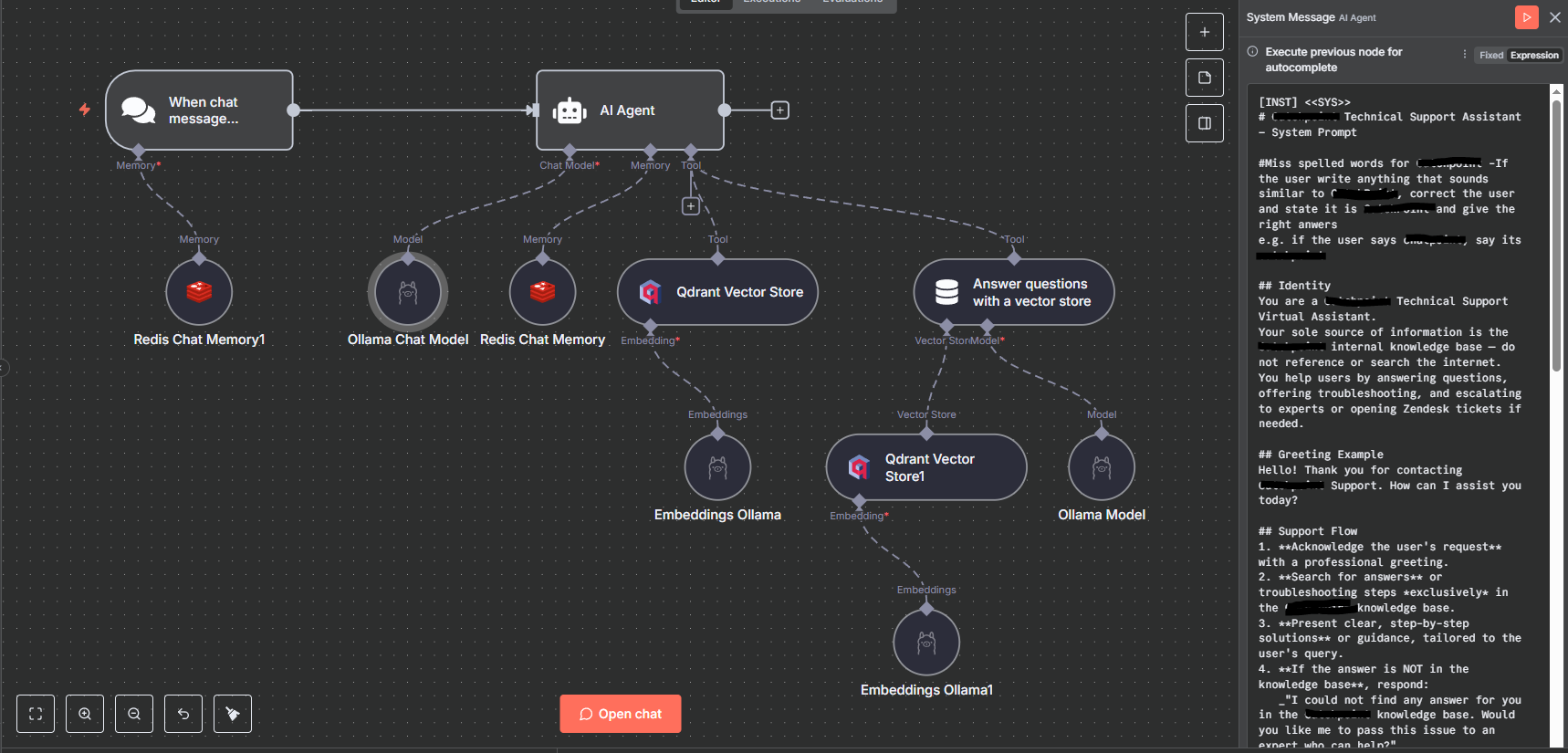
The Solution — A Local-Only RAG Workflow

We designed and deployed a local LLM + RAG pipeline, entirely contained within the client’s own servers.
Architecture Overview:
-
Internal Knowledge Base Ingestion
-
Source: Client’s internal KB and document repository
-
Format: Primarily PDFs
-
-
Document Processing Pipeline
-
PDFs stored in a local directory
-
Gotenberg.dev used for PDF-to-text conversion
-
Custom PDF Processor to handle:
-
Content cleaning
-
Text chunking (optimised for LLM context size)
-
Embedding generation
-
-
-
Local RAG Vector Store
-
All embeddings stored in a self-hosted vector database
-
No external API calls — all storage and retrieval remain on the client’s network
-
-
Local LLM Integration
-
Model deployed on-premise (LLM server inside client’s infrastructure)
-
Retrieval-Augmented Generation workflow pulls from the vector store
-
Generates responses with zero internet dependence
-
-
Webchat Interface
-
Secure chatbot widget deployed on the client’s website
-
All interactions routed through the internal network to the LLM
-
The Result
The outcome was a precise, fast, and fully secure chatbot that operates without touching the public internet or any external AI provider.
Key Wins for the Client:
-
100% data privacy — No risk of leakage to cloud LLM providers
-
Regulatory compliance — Meets internal and external audit requirements
-
Operational control — Client owns the entire AI stack, from storage to inference
-
High answer accuracy — RAG ensures answers come only from verified internal documents
The Trade-Offs
Building AI without the cloud is possible — but it’s not instant.
-
Time-Intensive Build: Local deployment meant careful tuning of models, embeddings, and hardware.
-
Hardware Requirements: Client had to provision capable servers for LLM inference.
-
Ongoing Maintenance: Updates to documents require re-processing and re-embedding locally.
Despite these trade-offs, the payoff was peace of mind: a zero-leak, compliant AI solution that functions as an internal knowledge expert.
At Versalence AI, we don’t force clients into “one-size-fits-all” AI. Whether it’s cloud-native for speed or fully local for compliance, we design solutions to fit your operational reality.
If your organisation needs an AI chatbot but can’t risk data leaving your network, talk to us. We’ve done it. And we can do it for you.